By Eric Picard (Originally published on AdExchanger.com, September 3, 2013)
Local advertising is the largest pool of dollars in the US advertising industry, but is also by far the most fragmented and complex marketplace.
EMarketer’s numbers below are fascinating. They show clearly that local advertising is massively larger than digital media overall, and while traditional local ad spending, at $109 billion in 2012, seems to be stagnating (I’m not sure I buy that by the way – I’ve seen charts like this before that expect local traditional to stagnate but it hasn’t), that pool of dollars is double the next largest media. This chart expects local digital to double in size by 2017, where it would sit in the same magnitude as the big-league spending areas, including display ads, search and television.

The problem with local as a category is that it’s a cross-section of every other media, including television, radio, print, digital and a variety of other media types. And the spending is wildly sliced up across many more advertisers than national media. In national media, roughly 9,000 advertisers make up more than 90% of spending across all media. In local, there are millions of businesses spending money. This points to a significant problem scaling spending, especially on the supply side of the market.
Local Advertising Eludes Large Players
Many companies over the years have taken a run at local in the digital space. They range from companies feeding the paid search listings with local business ads to local offers through companies like Groupon and media efforts like Patch that push digital news at the local level while driving ad sales at the national level. There have been hundreds, if not thousands, of companies dashed upon the shores of digital local for every company that’s had some measure of success. This isn’t shocking – startups have spectacular flameout rates – but it is clearly a space with unique hurdles that few have figured it out. Even those we could consider successful, such as Groupon, are widely scrutinized and criticized when it comes to how they’ll scale their business.
There are few models in digital that have scaled across large numbers of media buyers. The rule has been for the most part that other than paid search, there have been only marketplaces that scale on the supply side. Paid search has roughly 500,000 active advertisers participating in the various marketplaces – the main players today are Google and Bing. Google has done a great job of leveraging that advertiser set to apply their combined demand across other marketplaces, but even adSense is a comparatively small pool of spending compared to paid search. So the biggest game in town hasn’t conquered local advertising yet – and they seem far from doing so still, although much closer than in the past.
But there is already a huge amount of money spent on local advertising – with millions of participating companies and thousands of competing publishers. It’s a business that’s been in place for hundreds of years, but only in the last decade has it really suffered. In basic media theory we see that where audiences concentrate, media dollars will flow. Generally the theory is that media dollars flow in some proportion to the amount of time spent with those media. And where those things are out of whack, analysts talk about “upside opportunity.” Mary Meeker’s frequently updated deck talks about the disproportionate time spent on digital media vs. the dollars spent as an example of the opportunity in digital (lately she focuses a lot on mobile).
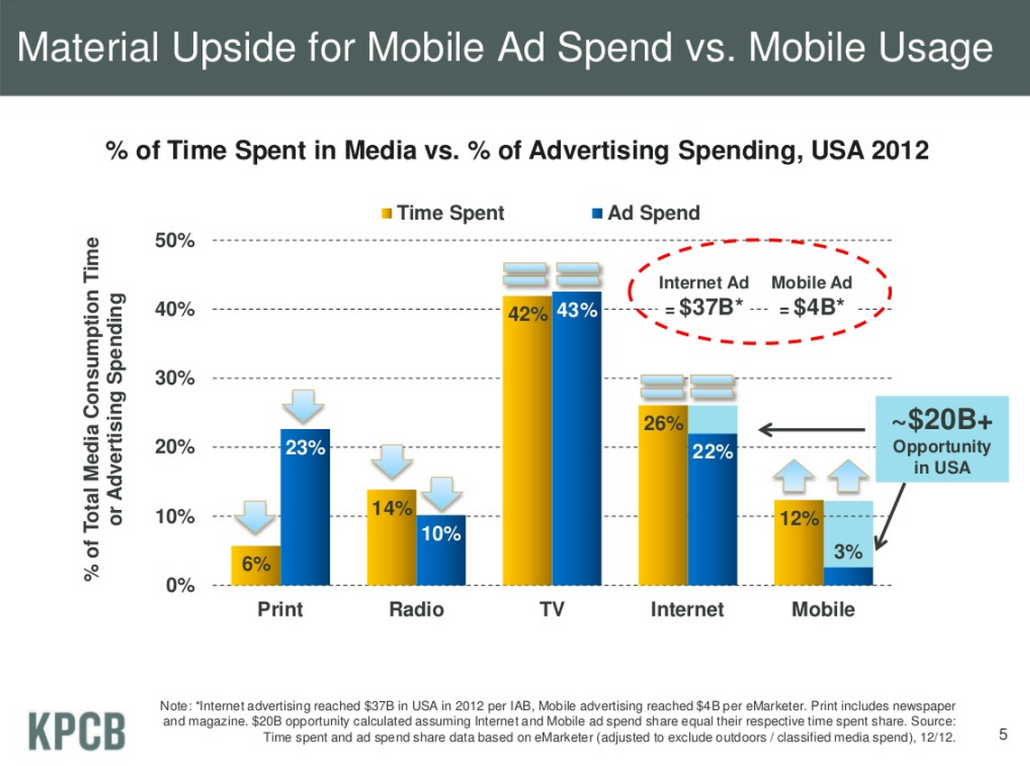
What I love and hate about this analysis is that while TV has always been a fairly even match against time and dollars spent and, until the last 10 years, radio was similarly matched, there’s always been a strange outlier on this deck. Print media has always looked basically like it does on this chart. This disparity is generally used by analysts to suggest that print media is doomed.
The problem with that analysis is that it’s deeply flawed and doesn’t take into account the reasons why print has such a disparity. When you dig into newspapers, this disparity is even greater. And the more locally you dig in, the greater the disparity – with local newspapers disproportionally getting more dollars than time spent.
The Art Of Selling Media
The reason for this is so simple that it’s rather shocking. My friend Wayne Reuvers, who founded LiveTechnology (a company most have never heard of because it focuses on local traditional media creative production and operates behind the scenes) is the most expert person I know on local media.
One of my favorite quotes of his: “National media is bought, local media is sold.”
What he means is that local advertising dollars are spent mostly by non-professionals, usually someone working within the local business. And as any local business owner will tell you, local media providers trying to sell advertising and marketing opportunities inundate them with sales calls.
National media salespeople generally don’t go out and pitch ad opportunities to media buyers, they respond to RFPs. While there’s plenty of outreach from sell side to buy side, it’s mainly evangelical – making sure the buyers understand what the publisher has to offer, often not a direct business pitch with an expectation of dollars on the line. This is maybe not so true for ad networks, but for publishers it’s generally true.
Newspapers are a category that has been around for hundreds of years, and are the oldest of the local media. The models are mature and extremely efficient. When I’ve talked to local businesses about how they spend advertising dollars and why they spend so much on newspapers compared to the other forms of media, they’ve generally said, “My sales rep at the paper is great, he or she knows me and knows what I need. It’s super easy to execute a buy there, they do almost all the work for me. They’ll even do the creative for me. I just need to pay them money.” Changing the offer or creative in newspaper buys is also easy, so if the buyer needs to focus sales on a loss leader product or have a new promotion, an ad change can be made in a day or two.
Local businesses often find the costs of television spots so high that they can’t be justified. And when they’ve tried to buy display advertising from big publishers, nobody returned their calls. Paid search works well for some businesses, but not so much for others. The only other place where local businesses consistently spend money is on yellow pages. Not surprisingly, this is another place where they are sold ad space constantly with reps who are frequently in touch and educating them on new ways listings are being pushed to digital media.
Reuvers believes that newspapers have dropped the ball in the move to digital. He calls newspapers the first local search engines, and has been so evangelical about their opportunity that he published a manifesto about five years ago to push local newspapers toward a winning model. It is a fascinating read – if a bit out of date – and basically says newspapers should own the space.
Tackling The Local Digital Conundrum
I believe a successful local play for digital dollars must include the following:
1. Local Salespeople
These salespeople should focus on the community and form relationships with local businesses, meaning both small and medium-sized mom-and-pop businesses and local locations or branches of national or regional companies. These national/local companies spend 80% of local ad dollars but have wide discretion about where they spend those dollars. When companies try to run at local with a national sales force, they often fail.
2. Self-Service
Local business owners without a lot of technical skills need streamlined ways to spend dollars in a self-service and lightly assisted way. Scale will come for those who figure out self-service, but finding a way for scalable assisted buying is critical to success.
3. Easy Updating
Local businesses need simple ways to update their advertising or offer based on what works for them. This may take the form of updating the creative message or changing the format. While not deeply analytical on what advertising works, most local businesses are surprisingly astute at understanding what works.
National digital folks tend to discount how well these local businesses understand the effectiveness of their ad dollars. Few local businesses can afford to waste ad dollars, so they are pretty careful about their spending.
That said, they have limited venues to spend money on so they generally can figure it out without much work. Groupon figured out the hard way that local businesses are not stupid about the economics of marketing. There has been a lot of backlash among businesses toward any sense of being taken advantage of, strong-arm tactics or salespeople who don’t understand their business.


